How the Eye Decides Where to Look (Before You Do)
Visual saliency is the eye's automatic pull toward motion, contrast, and faces. Learn to read it and steer gaze in every frame.

Your eyes don't scan a frame evenly. They jump to a few spots — fast, involuntary, before you've decided anything. That early targeting is called visual saliency, and unlike most of this craft, it's predictable.
TL;DR — Where the eye lands in a frame is mostly mechanical — motion, faces, and contrast win. Compose so the eye is pulled to the thing that matters, and you control the hook.
👁️ What saliency actually is
Saliency is what makes a region "stand out" enough to win the next eye movement. It's not a judgment about what's important.
It's a dumb, early calculation: what here is most different from its neighbors, right now?
That gap is the whole problem. Your frame can hold the punchline, the product, the proof — and if that spot isn't salient, the eye skips it.
Importance is what you decide. Saliency is what the visual system computes for you, like it or not.
The upside: saliency is stable. A bright moving object on a dark still background pulls a toddler, a grandparent, and a stranger scrolling at 2 a.m.
You're not guessing at taste. You're working with a mechanism — which is why getting it right in the first second is load-bearing, not finishing.
🧠 Bottom-up vs. top-down looking
Vision splits into two systems, and the split is the whole game for short-form:
- Bottom-up — reflexive, stimulus-driven. The eye is yanked toward whatever stands out: a bright spot, a moving object, a face. You don't choose it. It runs before you understand the image.
- Top-down — goal-driven. Once you know what you're hunting for, you steer your gaze: reading text, finding an object, following an argument.
In the first moment of a short video, bottom-up wins — the viewer is being served, not searching. So raw saliency decides where the eye lands before any intention kicks in.
That's why so many clips die before 3 seconds.
The open asks the viewer to work — read a title card, parse a slow setup — when they have no reason to yet.
🎯 What pulls the eye, ranked
Decades of attention research converge on a short list. They don't pull equally — keep the rough order in your head while framing.
| Feature | Pull | Why it works |
|---|---|---|
| Motion / change | Very strong | Movement signalled threat and opportunity long before cameras |
| Faces (especially eyes) | Very strong | We're wired to find and read faces fast |
| High local contrast | Strong | An edge against flatness is the eye's basic unit |
| Bright / saturated color on a muted field | Strong | Pop-out is literally a contrast effect |
| Center-ish placement | Moderate | A learned bias — the subject is usually near the middle |
| Text | Weak at first | The eye finds text, then slows to read it (top-down) |
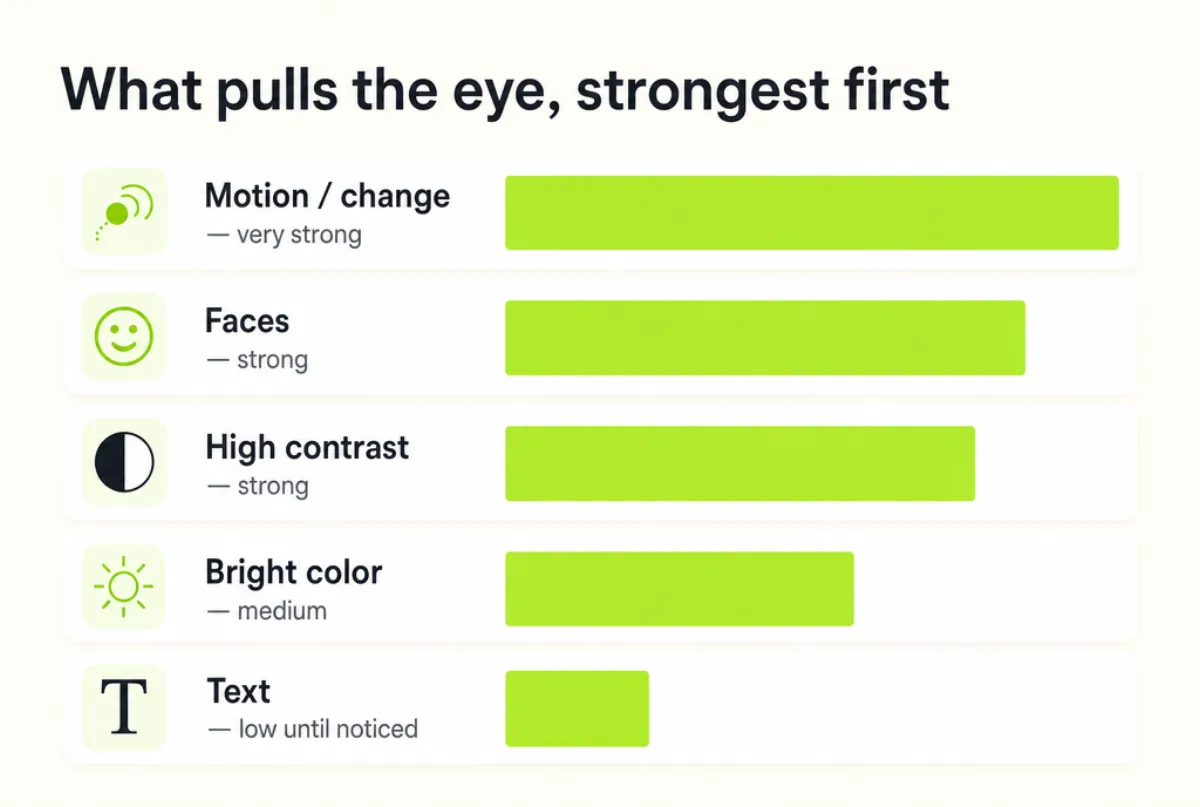 The eye doesn't weigh these equally. Motion and faces win; text loses the first beat, then takes over once reading starts.
The eye doesn't weigh these equally. Motion and faces win; text loses the first beat, then takes over once reading starts.
Three things fall straight out of that table.
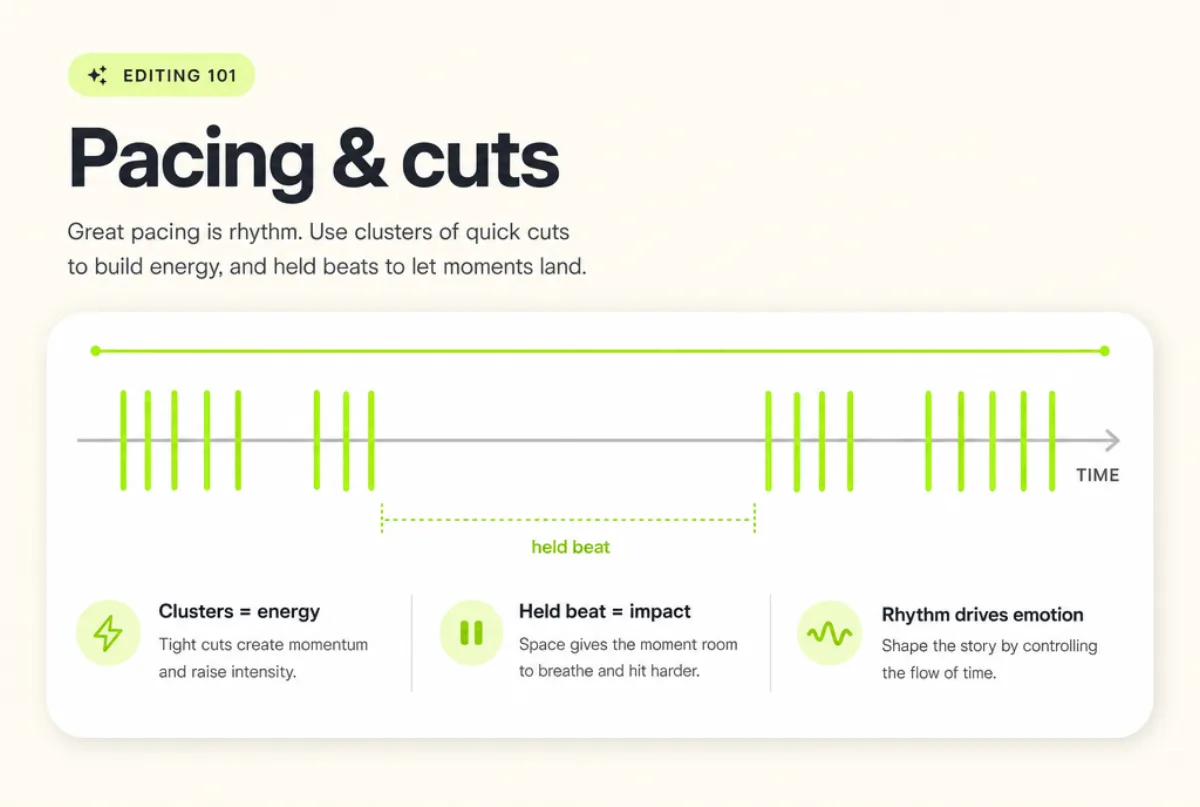
✂️ Motion is your strongest lever
Motion pulls hardest, so a moving subject on a still background is the most reliable way to control gaze. A static open is weak for the same reason: nothing moves, so bottom-up attention has nothing to grab.
This runs through pacing and cuts too — a cut is a sudden frame-wide change, which is why a well-timed edit re-grabs the eye even when the content is calm.
Give the eye something to track and you've taken the wheel.
😶 Faces are a magnet — and a trap
Faces draw the eye almost irresistibly, which is why so much short-form is shot to camera. But the magnet works whether you want it to or not:
- A face on a poster behind you
- A second person in the frame
- Even logos and objects in face-like arrangements
🔆 Contrast beats brightness
It's not absolute brightness that pulls the eye — it's local contrast, how different a spot is from its neighbors.
A bright subject in a bright frame doesn't pop. A modestly lit subject on a dark, simple background pops hard.
"Shoot against a clean background" isn't about looking tidy — it's about removing competitors for the eye.
📍 The center bias (your camera already knows it)
The eye drifts toward the center of the frame, especially on the first fixation. Drop someone into an image cold and their first movement is almost always toward the middle.
Two practical takeaways:
- Lean on it. Put what matters near center, or just above, to stack the bias on top of your contrast and motion.
- Don't rely on it. Nearly every creator already centers their subject, so center alone isn't distinctive. The eye lands there first, then leaves fast if nothing salient holds it.
Center buys the first glance for free. Contrast, motion, and faces convert that glance into a stay.
📈 Reading a saliency map
A saliency map is a model's best estimate of where the eye is pulled — bright where attention concentrates, dark where it doesn't. It tells you something you can't judge yourself, because you already know where you want people to look, and that knowledge contaminates your gaze.
You can't un-know your own intent. A model can. That's the entire reason to look at a heatmap instead of trusting your eye.
The one question to ask: does the heat land on the subject, or somewhere else? Three failure modes, all fixable:
- Split attention — heat divided between your subject and a competitor (a bright window, a busy background, a second face). The eye can't settle.
- Misplaced attention — heat on the wrong thing. Your subject sits in a dead zone while a distraction owns the brightest region.
- No clear target — heat smeared thinly everywhere. A flat, evenly-lit frame gives the eye nothing to grab. Reads as "boring" even when nothing's technically wrong.
 Split attention: the heat is divided between the subject and a bright window. The eye bounces, the frame doesn't resolve, and the viewer leaves.
Split attention: the heat is divided between the subject and a bright window. The eye bounces, the frame doesn't resolve, and the viewer leaves.
The fix is rarely dramatic — simplify the background, kill the competing highlight, relight so the subject is the brightest local region.
Small composition changes move the heat a long way. That's exactly what you want to test before you publish, not discover after.
⏱️ Saliency vs. holding over time
Saliency is a single-frame property — where the eye goes in this picture. But a video is a sequence, and winning the first glance isn't the same as keeping someone.
That's the difference between hook and hold: saliency governs most of the hook; holding depends on each new beat offering somewhere worth going.
Track per-frame saliency across a clip and sum it with motion and audio energy, and you get something close to an attention curve — a beat-by-beat read of where the video grips and slackens.
A salient frame that holds still too long still bleeds attention: the eye found the region and now has nowhere new to go.
The craft isn't "make every frame maximally salient." It's keep the salient region meaningful, and keep giving the eye a reason to move.
✅ A practical framing checklist
Run your opening keyframe through these before you publish. None need a tool; the tool just makes the answers honest.
- What's the brightest, highest-contrast region? Your subject — or a window, lamp, white wall?
- Is anything moving in the open? If the first frames are static, your strongest pull is sitting idle. Re-cut to land on motion.
- How many faces are in frame? Every extra face competes. Crop or blur background faces that aren't the point.
- Where would a stranger's eye go first? Not where you want it — where contrast and motion actually send it. This is the question your own knowledge can't answer.
- Does the salient region change over the first beat? A salient-but-static frame still bleeds. A cut or a movement keeps it from going stale.
The goal isn't a busy frame. It's a frame where the one thing that matters is also the one thing the eye is pulled to — then a sequence that keeps that alignment moving.
👀 Where this shows up in Scrollproof
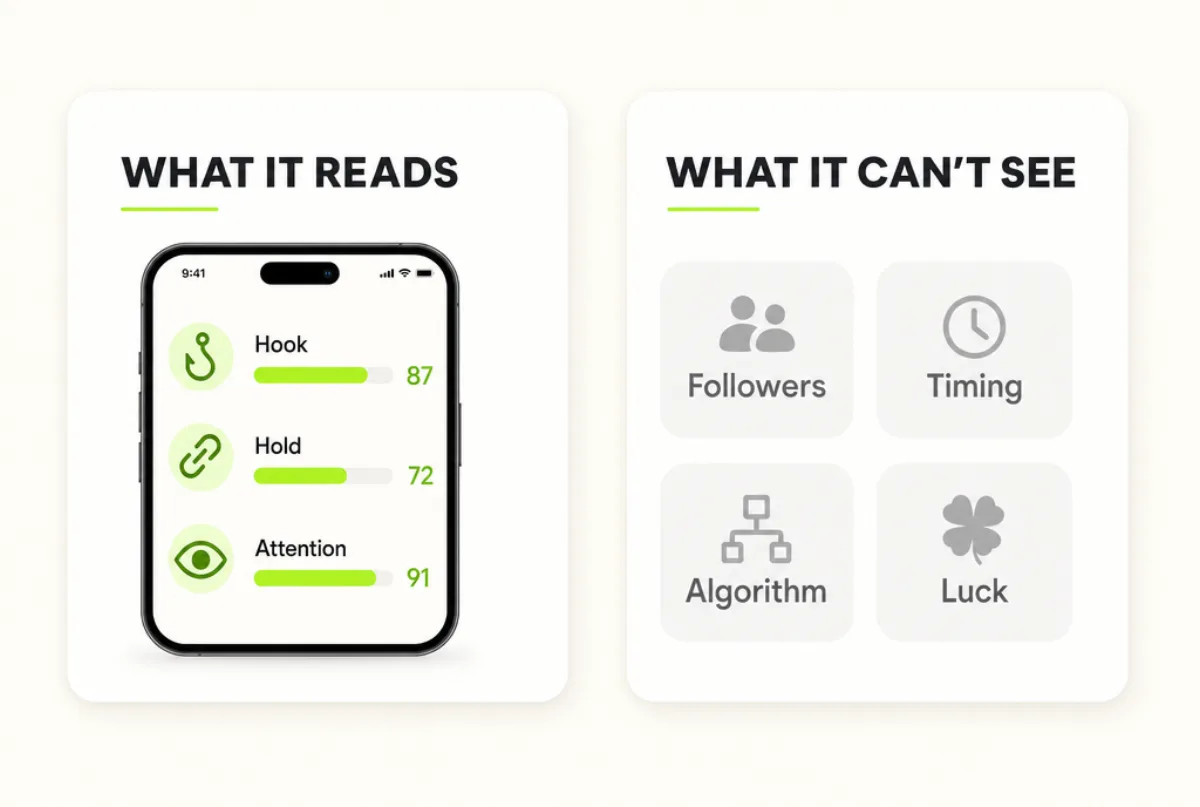
The attention heatmap in Scrollproof is exactly this: a visual-attention model drawn over your keyframes, built from real computer-vision analysis of contrast, motion, color, and faces.
It's an illustrative model of likely gaze — not a medical or neurological reading, and we're explicit about that line. Like any model, it's a prediction with limits, not a guarantee.
What it's genuinely good for is one check: is your frame steering the eye to the thing that matters, or are you quietly competing with your own image?
Run it as part of a pre-publish testing workflow, change one thing, and re-read.
When a read says the open is weak, saliency is one of the first levers in the field guide to fixing a flat start.
 The repair is usually small: simplify the background, remove the competing highlight, and the heat consolidates on the thing that matters.
The repair is usually small: simplify the background, remove the competing highlight, and the heat consolidates on the thing that matters.
Saliency is one of the rare places where the mechanism is stable and knowable. You can't control whether a video resonates.
But you can control where the eye lands in a frame — and in the first beat, that's most of the game.
Frequently Asked Questions
What is visual saliency in simple terms?
It's how much a region of an image grabs your eye automatically, before you consciously decide where to look. It's driven by motion, contrast, bright color, and faces — not by what's logically important.
It's the difference between what grabs the eye and what deserves it.
What pulls the eye most in a video frame?
Roughly: motion and change pull hardest, then faces, then high local contrast and bright color on a muted background.
Center placement and text are weaker — the eye finds text, then slows to read it (a different, goal-driven attention). A moving subject on a clean background is the most reliable control.
What is a saliency map or attention heatmap?
A model's estimate of where the eye is likely pulled, shown as a heatmap — bright where attention concentrates, dark where it doesn't. Drawn over your keyframe, it lets you check whether the eye lands on your subject or a distraction.
It's an illustrative model of likely gaze, not a recording of real viewers.
Why does my subject get ignored even when it's centered?
Because center only earns the first glance, not a sustained look. If your subject sits in a low-contrast area while something brighter owns the frame, the eye leaves immediately.
Almost everyone centers, so it isn't distinctive. The subject also needs to be the brightest, highest-contrast, or only-moving region to hold the eye.
Does high saliency mean my video will perform well?
No. Saliency governs where the eye goes in a frame — most of the involuntary stop, the hook.
But performance also depends on holding attention over time and on your topic's relevance to your audience.
A strong map means the eye is landing in the right place; it can't promise the video resonates or gets views.
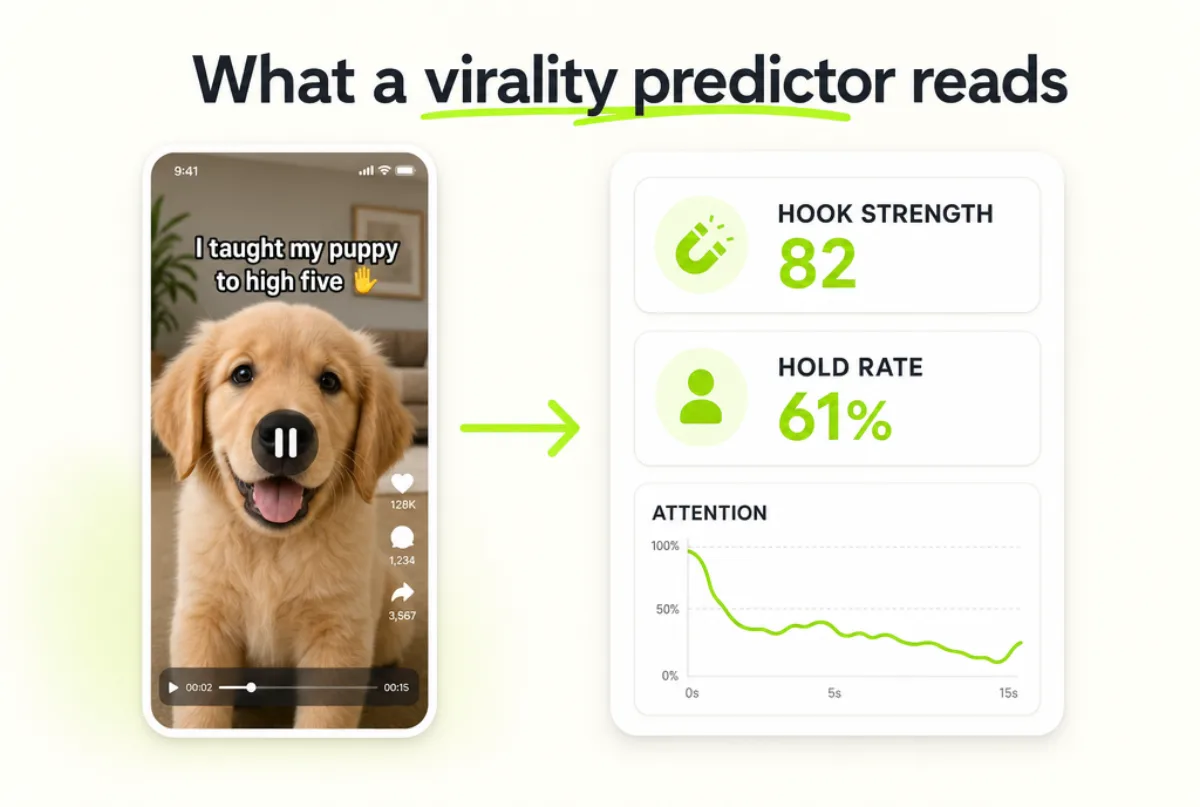
Want to see where the eye actually lands in your frames? Scan one free and read your attention heatmap before you publish.
Stop guessing. Scan the clip.
Drop a short video and get Hook Strength, Hold Rate, a second-by-second attention curve, and a real attention heatmap — in about a minute. First scans are free.